




Les protocoles
Les protocoles sont la base de la communication, non seulement sur Internet, mais aussi pour la téléphonie, les transactions bancaires... Je ne traiterais ici que des protocoles qui interviennent dans les communications Internet et télécom.
 internet internetDHCP (Dynamic Host Configuration Protocol) HTTP (HyperText Transfer Protocol) TCP (Transmission Control Protocol) UDP (User Datagram Protocol) |
télécom |
Qu'est ce que le DHCP ?
Définition
DHCP signifie Dynamic Host Configuration Protocol. Il s'agit d'un protocole qui permet à un ordinateur qui se connecte sur un réseau local d'obtenir dynamiquement et automatiquement sa configuration IP. Le but principal étant la simplification de l'administration d'un réseau.
On voit généralement le protocole DHCP comment distribant des adresses IP, mais il a été conçu au départ comme complément au protocole BOOTP (Bootstrap Protocol) qui est utilisé par exemple lorsque l'on installe une machine à travers un réseau (on peut effectivement installer complètement un ordinateur, et c'est beaucoup plus rapide que de le faire en à la main). Cette dernière possibilité est très intéressante pour la maintenance de gros parcs-machines.
Les versions actuelles des serveurs DHCP fonctionne pour IPv4 (adresses IP sur 4 octets). Une spécification pour IPv6 (adresses IP sur 16 octets) est en cours de développement par l'IETF.
Références
Les incontournables RFCs :
- RFC951 : BOOTP
- RFC1497 : options vendor extensions
- RFC1541 : Définition du protocole DHCP
- RFC1542 : interaction entre BOOTP et DHCP
- RFC2131 : complète et remplace la RFC1541
- RFC2132 : complément aux options vendor extensions
Le protocole HTTP
HTTP signifie HyperText Transfer Protocol. C'est le protocole qui est utilisé sur Internet pour transmettre les pages web.
Ce protocole à été conçu il y a un certain temps (en 1991, au tout début du Web) par le père-même du Web : Tim Berners-Lee. Il a été conçu dans le but de distribuer les pages web sur un réseau TCP/IP, comme Internet. Aujourd'hui, nous en sommes à la version 1.1 du protocole. Il est entièrement défini dans les RFCs.
C'est un protocole de niveau 5 sur le modèle OSI, au même titre que FTP ou telnet. Ce protocole a le mérite d'être très simple et humainenement compréhensible.
Références
Les RFCs :
- RFC1123 : Requirements for Internet Hosts -- Application and Support
- RFC1945 : HTTP/1.0
- RFC2616 : HTTP/1.1
- RFC2617 : HTTP Authentication: Basic and Digest Access
- RFC1867 : Form-based File Upload in HTML
Cette rubrique a largement été inspirée du cours de M. Muller, professeur à l'Ecole Centrale de Lyon. Merci à lui.
Le protocole TCP
D'après SebF - www.FrameIP.com
Définition du protocole
Le protocole TCP (Transmission Control Protocol) est un protocole de couche 4 s'appuyant sur IP. Contrairement à UDP, C'est un protocole conçu pour répondre à des besoins importants en terme de qualité de service. En effet, TCP fournit entre autres une notion de session (d'où le terme "mode connecté") et de contrôle d'erreurs. Ce protocole est donc utilisé partout sur Internet, dès lors que la conservation de l'intégrité des données à transmettre est plus important que la donnée elle-même :
- Echange de mails : le protocole SMTP, chargé du transport des mails, s'appuie sur TCP pour les échanges sur Internet.
- Les transferts de fichiers sur Internet se font par FTP qui s'appuie sur TCP, contrairement à TFTP qui s'appuie sur UDP (voir UDP). De la même façon, les protocoles peer-to-peer s'appuient sur TCP.
- etc.
TCP étant beaucoup plus couteux qu'UDP (paquets plus gros, ouverture et fermeture de sessions, etc.), son utilisation
peut nécessiter des infrastructures réseau importantes. C'est ainsi que le protocole HTTP,
initialement compatible avec UDP, a pris en compte la fermeture de connexion (en-tête Connection: keep-alive)
afin d'optimiser les ouvertures et fermetures de sessions TCP, et permettre ainsi de charger plus vite les pages Web.
Structure de l'en-tête TCP
Les champs de l'en-tête
La structure de l'en-tête TCP est la suivante :
Cet en-tête finit par des options . Le nombre d'options étant variable, il est juste précisé que la taille totale du segment d'option doit être un multiple de 32 bits. C'est pourquoi ce champ d'options finit par une zone de bourrage (voir ci-après).
Les champs de cet en-tête sont :
- Port source : codé sur 16 bits, il correspond au port relatif à l'application en cours sur la machine source (et qui émet donc cette trame TCP)
- Port destination : codé sur 16 bits, il correspond au port relatif à l'application en cours sur la machine de destination.
- Séquence : codé sur 32 bits, il correspond au numéro du paquet. Cette valeur permet de situer à quel endroit du flux de données le paquet doit se situer par rapport aux autres paquets.
- Numéro d'ACK : codé sur 32 bits, il définit un accusé de réception (acknowledgement en anglais) pour les paquets reçus. Cette valeur signale le prochain numéro de paquet attendu par l'émetteur de ce paquet. Par exemple, s'il vaut 1500, cela signifie que tous les datagrammes dont le numéro de séquence (champ précédent) est inférieur à 1500 ont été reçus. Une fois les connexions établies, ce champ est toujours indiqué.
- Offset : codé sur 4 bits, il définit le nombre de mots de 32 bits que contient l'en-tête TCP. Ce champ indique donc où les données commencent dans le datagramme IP courant et permet de déduire la longueur totale du champ d'options.
- Réservé : 6 bits sont réservés pour utilisation ultérieure. Ces bits doivent être à 0.
- Bit de contrôle :
URG: indique que le champ Pointeur de donnée urgente est utilisé.ACK: indique que le numéro de séquence pour les acquittements est valide.PSH: fonction Push : indique au récepteur de délivrer les données à l'application et de ne pas attendre le remplissage complet des tampons.RST: utilisé pour demander la réinitialisation de la connexion.SYN: indique que les numéros de séquence sont synchronisés.FIN: indique la fin de transmission.
- Fenêtre : codé sur 16 bits, il correspond au nombre d'octets à partir de la position marquée dans l'accusé de réception que l'émetteur du paquet peut recevoir. Le destinataire de ce paquet (et donc futur émetteur) ne doit donc pas envoyer les paquets apràs "numéro de séquence + fenêtre".
- Checksum : codé sur 16 bits, il représente la validité du paquet de la couche TCP. Le détail de ce calcul est précisé plus bas.
- Pointeur (de donnée urgente) : codé sur 16 bits, il communique la position d'une donnée urgente en donnant son décalage par rapport au numéro de séquence. Le pointeur doit pointer sur l'octet suivant la donnée urgente. Ce champ n'est interprété que lorsque le flag URG est marqué à 1. Dès que cet octet est reçu, la pile TCP doit envoyer les données à l'application.
La zone d'options est construite de la façon suivante : une option doit commencer sur un nouvel octet et doit être un multiple de 8 bits. Toutes les options sont prises en compte par le Checksum. Il existe deux formats types pour les options :
- Cas 1 : option mono-octet (codé sur un octet).
- Cas 2 : option multi-octet : octet de type d'option, octet de longueur d'option (indiquant la longueur totale de cette option, pas uniquement la longueur de la valeur), octets de valeur d'option.
La liste d'options pouvant ne pas occuper un multiple de 32 bits, des bits de "bourrage" peuvent être nécessaires pour complet le segment d'options jusqu'à un multiple de 32 bits. Ces bits de bourrage ont toujours la valeur 0.
Calcul du checksum
Le checksum est déterminé en calculant le complément à 1 sur 16 bits de la somme des compléments à 1 des octets de l'en-tête (hors checksum) et des données pris deux par deux (mots de 16 bits). Si le message entier contient un nombre impair d'octets, un octet "vide" supplémentaire (huit 0), non transmis, est ajouté à la fin du message pour terminer le calcul du checksum. Lors du calcul du checksum, les positions des bits attribués à celui-ci sont marquées à 0.
L'en-tête utilisé pour le calcul du checksum contient en fait un pseudo en-tête de 96 bits préfixé au véritable en-tête TCP. Ce pseudo en-tête comporte les adresses Internet source et destination, le type de protocole (TCP = type 06) et la longueur du message TCP. Le fait d'ajouter ce pseudo en-tête pour le calcul permet de protéger TCP contre les erreurs de routage.
Note : MBZ = Must Be Zero. Octet "vide", ne contenant que des 0.
La longueur figurant dans ce pseudo en-tête est la longueur totale du véritable en-tête TCP (c'est-à-dire que l'on ne tient pas compte des 12 octets supplémentaires de ce pseudo en-tête).
Références
Site de référence pour les protocoles IP (et site d'où est tiré cet article) :
- FrameIP
Les RFCs :
- RFC793 : Transmission Control Protocol
- RFC3168 : The Addition of Explicit Congestion Notification (ECN) to IP. Complète la RFC793.
- RFC768 : User Datagram Protocol
Le protocole UDP
D'après SebF - www.FrameIP.com
Définition du protocole
Le protocole UDP (User Datagram Protocol) est un protocole de couche 4 s'appuyant sur IP. C'est un protocole qui a été conçu pour être simple et rapide. Ainsi, il n'ouvre pas de session (d'où son appellation de "mode non connecté") et n'effectue pas de contrôle d'erreur (d'où son manque de fiabilité).
Ce protocole peut donc être a priori jugé moins intéressant que TCP. Cependant, ses champs d'applications sont larges :
- Lorsque les couches sous-jacentes peuvent palier à son manque de fiabilité. C'est le cas notamment avec TFTP (Trivial File Transfer Protocol) sur les réseaux locaux : en effet, la qualité des réseaux locaux est suffisamment bonne pour compenser les défauts d'UDP et permettre ainsi le transfert de fichiers à très haut débit.
- Pour transmettre de très faibles quantités de données lorsque le coût d'établissement et de maintien d'une connexion fiable est jugé trop important par rapport à ce qu'il y a à transmettre.
- Pour les applications satisfaisant à un modèle de type "interrogation réponse", la réponse étant utilisée comme un accusé de réception à l'interrogation. On y trouve classiquement SNMP (Simple Network Management Protocol) et DNS (Domain Name Server).
- Lorsque la vitesse de transmission a plus d'importance que la perte d'un paquet de données. C'est le cas d'un service tel que la voix sur IP où en effet, l'envoi en temps réel est primordiale, et la perte d'une trame d'information ne déformera pas notoirement le message transmis (l'oreille humaine sera capable d'extrapoler la perte de cette information).
Structure de l'en-tête UDP
Les champs de l'en-tête
La structure de l'enitête UDP est la suivante :
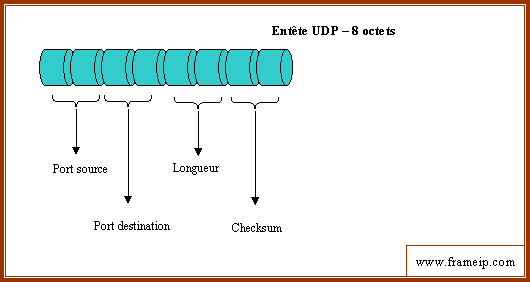
En-tête UDP
Les champs de cet en-tête sont :
- Port source : codé sur 16 bits, il correspond au port relatif à l'application en cours sur la machine source (et qui émet donc cette trame UDP)
- Port destination : codé sur 16 bits, il correspond au port relatif à l'application en cours sur la machine de destination.
- Longueur : codé sur 16 bits, il représente la taille de l'en-tête et des données. Son unité est l'octet et sa valeur maximale est 64 Koctets (216).
- Checksum : codé sur 16 bits, il représente la validité du paquet de la couche UDP. Le détail de ce calcul est précisé ci-après.
Calcul du checksum
Le checksum est déterminé en calculant le complément à 1 sur 16 bits de la somme des compléments à 1 des octets de l'en-tête (hors checksum) et des données pris deux par deux (mots de 16 bits). Si le message entier contient un nombre impair d'octets, un octet "vide" supplémentaire (huit 0), non transmis, est ajouté à la fin du message pour terminer le calcul du checksum. Lors du calcul du checksum, les positions des bits attribués à celui-ci sont marquées à 0.
L'en-tête utilisé pour le calcul du checksum contient en fait un pseudo en-tête de 96 bits préfixé au véritable en-tête UDP. Ce pseudo en-tête comporte les adresses Internet source et destination, le type de protocole (UDP = type 17) et la longueur du message UDP. Le fait d'ajouter ce pseudo en-tête pour le calcul permet de protéger UDP contre les erreurs de routage.
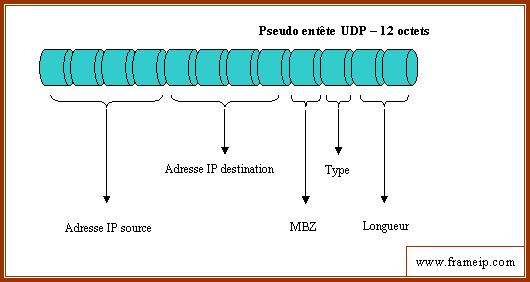
Pseudo en-tête UDP pris en compte dans le calcul du checksum
Note : MBZ = Must Be Zero. Octet "vide", ne contenant que des 0.
La longueur figurant dans ce pseudo en-tête est la longueur totale du véritable en-tête UDP (c'est-à-dire que l'on ne tient pas compte des 12 octets supplémentaires de ce pseudo en-tête).
Références
Site de référence pour les protocoles IP (et site d'où est tiré cet article) :
- FrameIP
Les RFCs :
- RFC768 : User Datagram Protocol
- RFC793 : Transmission Control Protocol
Copyright © 2019 themanualpage.org - Ce site est soumis aux conditions décrites dans les licences GNU GPL et FDL.
For best web hosting promotions, visit Blue Host Pricing Best Siteground Offer 2019 Hostpapa Wordpress WPEngine Coupon Code - Save 30% Godaddy Web Hosting A2 Hosting Coupon